Mooie voorbeelden van Data Science komen vaak van bedrijven die al ver zijn in hun ontwikkeling op het gebied van het gebruik van data. Voor sommige organisaties zijn dit soort voorbeelden heel relevant en direct toepasbaar, maar dat geldt niet voor elke organisatie. In dit artikel van de DDMA commissie Data, Decisions en Engagement beschrijven we hoe je business impact kunt realiseren in verschillende fases van de ontwikkeling van je datastrategie aan de hand van een aantal basisprincipes en het ‘people, process & technology’-model.
Drie basisprincipes als start om data professioneel in te zetten
Onafhankelijk van de volwassenheid van het datagebruik binnen jouw organisatie bestaan er drie basisprincipes die je kunnen helpen data professioneel in te zetten. Naarmate je volwassenheid groeit, worden deze principes op een andere manier ingevuld.
- Stel de business uitdaging centraal; een datateam moet vraagstukken oplossen die business impact hebben, en daarom zeer nauw met de business samenwerken. Anders raakt zij los van de bedrijfsvoering en zal de toegevoegde waarde beperkt zijn. Zorg ervoor dat je niet alleen focus hebt op het optimaliseren van een model, maar altijd het einddoel voor ogen houdt: de impact van het model op de omzet van je organisatie.
- Neem kleine stapjes, die snel waarde creëren voor de business. Bedrijven die net beginnen met het gebruiken van data kunnen simpele dataproducten ontwikkelen, zoals een helder dashboard met een overzicht van de belangrijkste KPI’s. Ook voor meer geavanceerde bedrijven blijft het van belang om constant waarde te blijven leveren en succesjes te vieren.
- Een sponsor op MT niveau, die bezwaren wegneemt en een visie uitdraagt waarin het belang van het slim inzetten van data benadrukt wordt. Deze support heeft elk datateam nodig omdat dataprojecten ook weerstand kunnen oproepen. Bijvoorbeeld omdat medewerkers bang zijn dat hun werk geautomatiseerd zal worden, of omdat het verzamelen, ontsluiten en analyseren van data veel tijd kan kosten.
People, process & technology
Het ‘people, process & technology’-model is een handig middel om organisatieveranderingen overzichtelijk in kaart te brengen. Door te kijken naar drie aspecten – people, process & technology – van Data-Science-projecten zorg je ervoor dat verbeteringen efficiënt worden doorgevoerd.
1. People – Zorg dat je met Data Science de business niet uit het oog verliest
Organisaties die Data Science toepassen starten meestal niet met een groot datateam, maar bouwen dat in een aantal fases op. Vaak start het professionele gebruik van data in bedrijven met data analisten die onderdeel zijn van business teams, zoals marketing. De analist draait volledig mee, en is constant bezig met het oplossen van businessvraagstukken, bijvoorbeeld door dashboards te ontwikkelen of analyses te maken op sales of retentie. In een volgende fase richten veel bedrijven aparte datateams op. Dat heeft veel voordelen, zoals het hanteren van gelijke definities en technologie voor de verschillende businessteams en het uitwisselen van kennis. Maar het heeft ook een potentieel nadeel, namelijk verwijdering van de business. Zorg bij zo’n opzet dat je een aantal vooruitgeschoven data mensen hebt die onderdeel zijn van business teams. Organisaties die zich verder ontwikkelen en aan de slag gaan met het opzetten van geavanceerde analytische modellen, zorgen ervoor dat er ook mensen zijn die langere tijd, vaak 6 tot 12 maanden, achter elkaar aan het model kunnen werken zonder dat ze afgeleid worden door de hectiek van de business. In die fase van volwassenheid zijn er vaak specifieke functies die als doel hebben om als schakel te fungeren tussen de business en de Data Scientists.
2. Proces – Een dataproject van Discovery tot Deployment
Het proces voor een dataproject bestaat uit een aantal stappen die sterk kunnen verschillen in complexiteit, afhankelijk van het aantal mensen dat aan het project werkt en de volwassenheid van de organisatie. De ervaring leert dat deze fases explicieter doorlopen worden en meer tijd kosten bij grotere organisaties en complexere projecten. Bij voorkeur wordt agile gewerkt, zodat er in korte cycli constant bijgestuurd kan worden. De stappen uit in een dataproject bestaan uit:
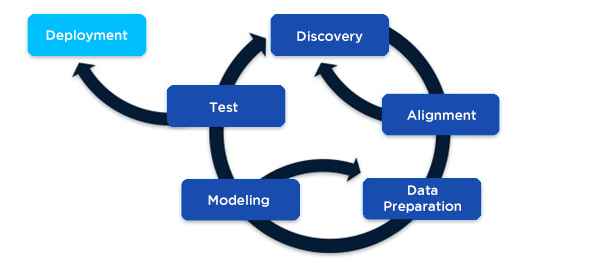
Discovery
De eerste stap in een dataproject is het formuleren van een duidelijk doel. Daarvoor worden de behoeftes uit de business opgehaald. Dit is de zogenaamde discovery-fase, waarin je in een interactieve sessie met de belangrijkste stakeholders een MVP (Minimal Viable Product) en scope bepaalt. In deze fase wordt ook bekeken wat er al aan data en modellen voorhanden zijn om de businessvraag te beantwoorden, en wat er nog ontwikkeld moet worden.
Alignment
In de alignment-fase wordt vervolgens de definition of success geformuleerd, met hypotheses en een planning. In deze fase definieer je ook een stakeholder map: wie zijn de belangrijkste stakeholders en wie maken de beslissingen? Met hen wordt constant afgestemd, om draagvlak te behouden en op basis van hun wensen bij te sturen.
Data preparation
De volgende fase is de datapreparatie. Tijdens deze fase gaan Data scientists grasduinen in de data om de datastructuur en de meest waardevolle data in kaart te brengen. Ook valideren zij de data en verwijderen ze de outliers. Hiervoor wordt afgestemd met de belangrijkste stakeholder. Tijdens het valideren van de data is het ook handig om een eenvoudige correlatieanalyse uit te voeren om de verbanden tussen de verschillende variabelen te herkennen en te verklaren.
Modeling
In de modelleerfase wordt er een model gebouwd. Met alle software die er tegenwoordig beschikbaar is, is dit niet eens meer zo ingewikkeld. Wel is het belangrijk om te kijken naar de verschillende type modellen en welk model het best past bij het business doel. Voorbeelden van modellen zijn het:
- Classification model, voor een Next Best Offer berekening
- Clustering model, voor klantsegmentaties
- Forecast model, voor pricing-modellen
- Time series model, voor het voorspellen calls naar het servicecenter
- Recommender model (collaborative filtering), om producten te promoten op basis van getoonde interesse (‘wie dit kocht, kocht ook…’)
- Outliers model, voor fraude-detectie
Afhankelijk van het model kun je naar verschillende (statistische) waarden kijken om de kwaliteit en de voorspellende waarde van het model te toetsen, zoals de Accuracy, Confusion matrix, Root Mean Squared Error, Gain- en Lift charts en R-squared.
Evaluatie en afstemming met de stakeholders is ook in deze fase van groot belang, om te waarborgen dat de focus op het eindresultaat en de business impact blijft liggen. Data scientisten kunnen zich nogal eens verliezen in de nieuwste technieken en het optimaliseren van de performance, en daardoor het einddoel uit het oog verliezen.
Test
In deze fase combineer je de intelligentie van het model met de kennis uit de business om een testplan te maken. Zo test je of een model geschikt is om business impact te genereren. Want een model op zichzelf levert niets op. Al kun je nog zo goed voorspellen welke klanten gaan opzeggen, dit helpt nog niet om te voorkomen dat ze opzeggen. Met een testplan meet en verbeter je de effectiviteit van het model voor de businesstoepassing. Idealiter toets je een model met vier verschillende groepen: twee controlegroepen (één met model en één volledig random) en twee campagnegroepen (één met suggereerde actie en één zonder). Door deze vier doelgroepen en resultaten te vergelijken kun je model-performance en de effectiviteit voor de toepassing (bijvoorbeeld een campagne) beoordelen.
Deployment
Bij goede resultaten in de testfase is de laatste stap het automatiseren van het model. In de deployment-fase breng je het model in productie. De datastromen worden geautomatiseerd, het model draait periodiek en de resultaten worden teruggekoppeld naar de business teams, die er acties op ondernemen.
Of je deze fases stapsgewijs doorloopt is, zoals eerder gezegd, afhankelijk van de maturiteit van de organisatie op het gebied van Data Science. Een individuele analist in een marketingteam zal niet al deze stappen doorlopen als hij of zij een dashboard bouwt. In grotere organisaties waar het ontwikkelen van complexe modellen vaker gebeurt, zijn alle processtappen cruciaal.
3. Technologie – Data Science wordt makkelijker en toegankelijker
Op het gebied van technologie zien we een aantal ontwikkelingen. Allereerst wordt Data Science makkelijker door de beschikbare software. Met “no-code” tooling zoals Rapid Miner, Dataiku of KNIME kan je zonder enige data- of programmeerervaring data prepareren, modellen testen, optimaliseren, resultaten vergelijken en het beste model in productie brengen. Toch blijft kennis over datastructuren, statistiek en de logica achter dit soort modellen noodzakelijk. Als je niet snapt wat er onder de motorkap gebeurt of uitkomsten niet goed kunt interpreteren, sla je al snel de plank mis door bijvoorbeeld modellen te “overfitten”. Naast makkelijker wordt Data Science ook toegankelijker, door bijvoorbeeld de integratie van Data-Science-functionaliteiten binnen cloud-omgevingen. Denk bijvoorbeeld aan functionaliteiten als: AWS Personalize, Google Recommendations AI en Azure GPT3 en marketing suites als Salesforce en Selligent.
Doordat Data Science ogenschijnlijk makkelijker en toegankelijker wordt, kan het beeld ontstaan dat straks elke marketeer zelf voorspellende modellen in elkaar kan klikken, bijna zoals die een PowerPoint presentatie maakt. Wij verwachten dat echter niet. De kennis van Data Science zal noodzakelijk blijven voor het ontwikkelen van betrouwbare en robuuste data toepassingen, en het op een goede manier doorlopen van de stappen zoals die hierboven beschreven staan. De rol van Data Scientist kan echter wel veranderen. De nadruk voor de Data Scientist zal minder komen te liggen in het schrijven van de code voor het model, en meer op het exploreren van de mogelijkheden met data, het begeleiden van het proces, sparren met de business en het bepalen welk model het best ingezet kan worden voor het businessdoel. De Data Scientist zal zijn of haar beeldscherm vaker dichtklappen en een rondje gaan wandelen met marketeers, controllers, managers of andere specialisten uit de business. Het vak van de Data Scientist was al een sexy beroep, volgens Thomas Davenport, maar wordt in toekomst misschien wel onweerstaanbaar.
Key takeaways
Er ontstaan steeds meer mogelijkheden op het gebied van Data Science en het inzetten ervan wordt makkelijker en laagdrempeliger. Dit biedt voor veel organisaties kansen die er eerder niet waren. We hopen dat dit artikel uiteenlopende organisaties helpt met het effectief inrichten van hun Data-Science-activiteiten en de handvatten biedt voor het behalen van business resultaten door slim gebruik van data. Hieronder vind je de belangrijkste takeaways:
- Je hebt business impact met Data Science als je constant focus houdt op het eindresultaat: de businesstoepassing van modellen of andere dataproducten
- Voor elke organisatie die professioneel met data werkt gelden een paar basisprincipes: zet de business uitdaging centraal, neem kleine iteratieve stappen, zoek een sponsor, liefst op MT niveau
- Bedrijven beginnen niet met een groot data team, maar meestal met analisten in businessteams. Ze evolueren vaak naar gespecialiseerde data teams met brugfuncties naar de business.
- Het proces van dataprojecten bestaat uit verschillende fases. In elke fase wordt de business betrokken. Of en hoe organisaties alle fases in de praktijk doorlopen worden hangt af van de maturiteit van de organisatie en de complexiteit van het data product.
- Data Science wordt makkelijker en toegankelijker. De rol van Data Scientists blijft onverminderd belangrijk, maar verandert wel.

Joyce Thomas

Vinça Mattens

Mark van der Vlies

Matthijs van de Peppel

Jimmy de Vreede
Ook interessant

AI in marketing: van praten naar doen – hoe je écht aan de slag gaat

Media Effectiviteits Meting (MEM): Essentieel voor Efficiënte Groei
